|
Zhi Zuo INTJ / 历史 / 天文 / 游戏 / 音乐 I'm a second-year master's student in Computer Science and Tecnnology at the Nanjing University of Aeronautics and Astronautics (2023-2026), advised by Prof. Pan Gao at Immersive and Interactive Multimedia Lab (I2ML). My current research interests are 3D vision tasks, especially 3D/4D generation/reconstruction and 3D/4D understanding. I am also interested in learning representations. NEWS! I am applying for PhD in Fall 2026, feel free to contact me ⬇ |

|
Research* indicate an equal contribution. |
|
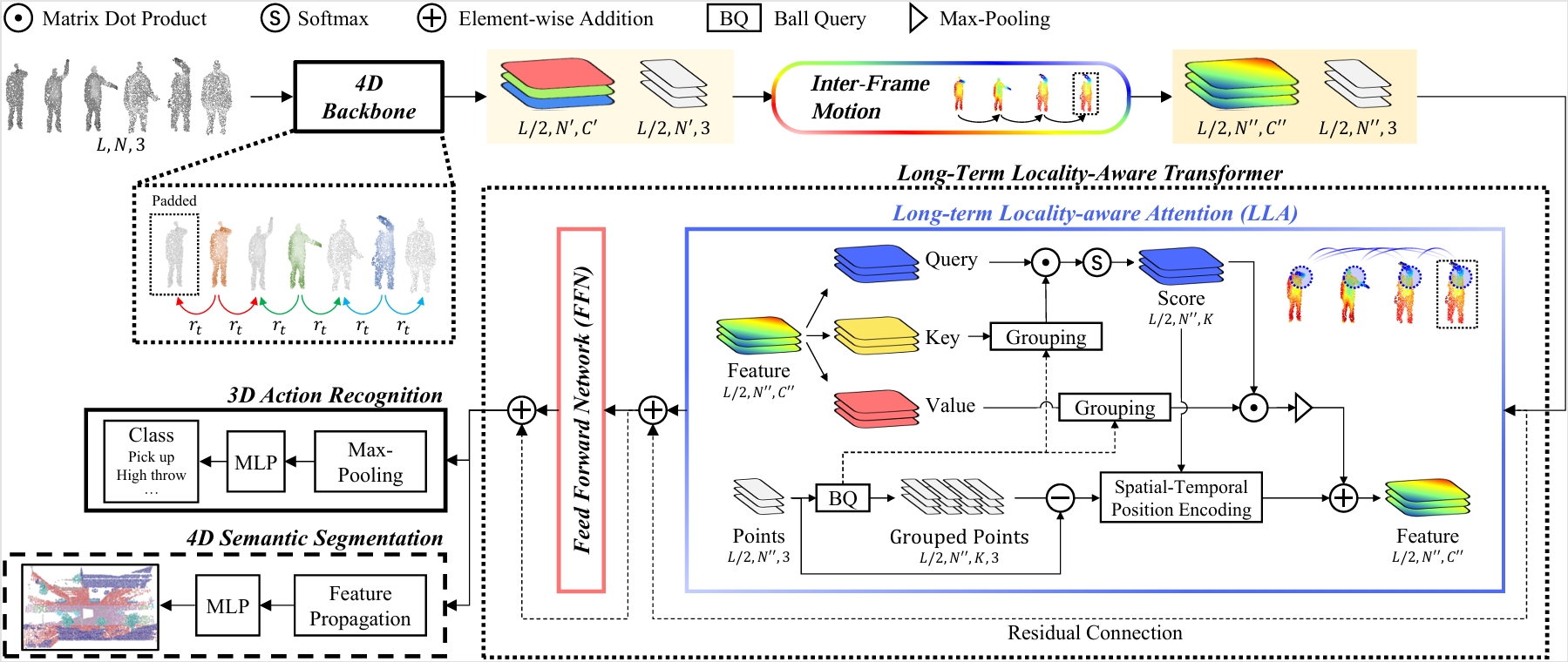
Point Long-Term Locality-Aware Transformer for Point Cloud Video Understanding.
Zhi Zuo, Pan Gao, Kang You, Wei Xiang, Jie Qin. In ACM MM Asia Workshops Design inter-frame motion moudle and long-term locality-aware attention to achieve the better performance on 4D action recognition and 4D semantic segmentation. code / |
|
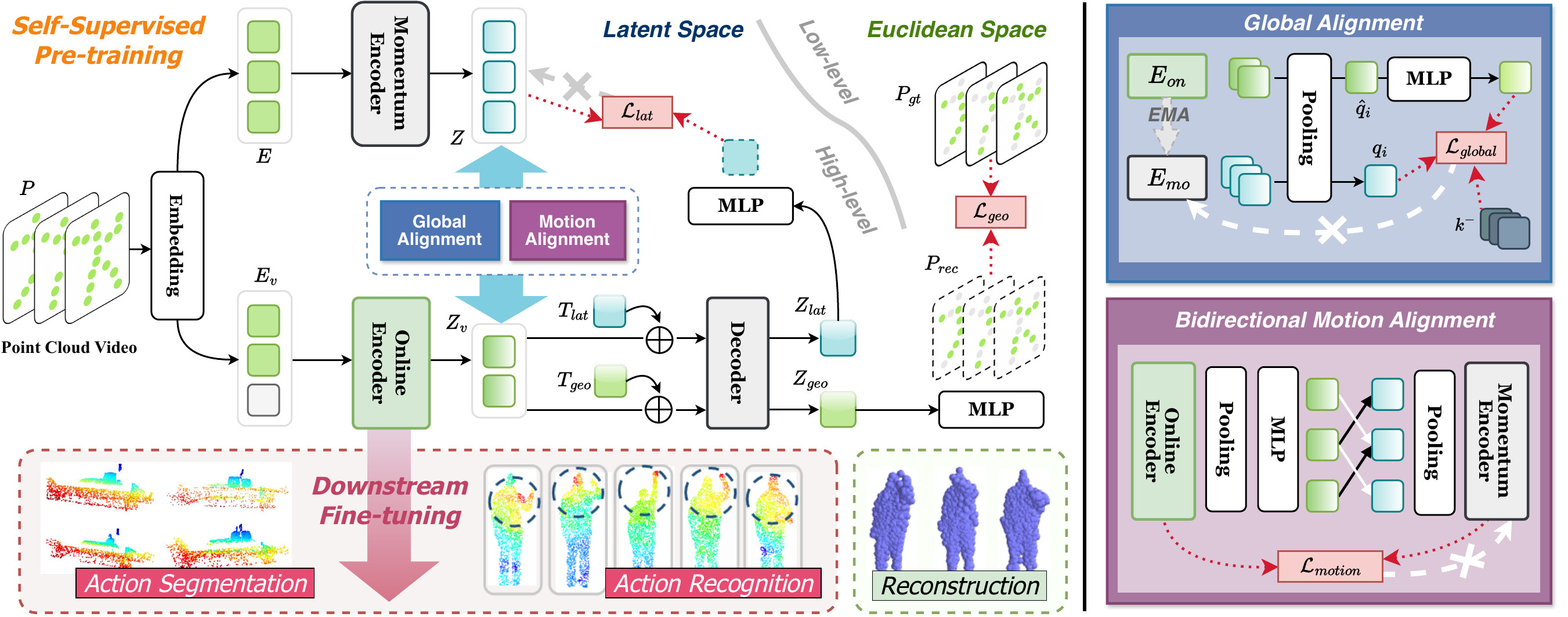
Disco4D: Towards Prior-Free Motion Representation Learning for Point Cloud Videos via Self-Disentangled Contrastive Pre-training
Zhi Zuo* , Chenyi Zhuang* , Pan Gao, Jie Qin. Hao Feng, Nicu Sebe, Under Review Design a novel self-disentangled MAE for point cloud videos that decomposes low-level feature and high-level feature with two different tokens to learn the meaningful and transferable motion representations for fine-tuning in down-stream tasks. arXiv |

|
WonderVerse: Video Geometric Correction and Enhancement for Extendable 3D Scene Generation.
Hao Feng*, Zhi Zuo*, Jia-Hui Pan, Ka-Hei Hui, Yihua Shao, Qi Dou, Wei Xie, Jingyu Hu, Zhengzhe Liu. In CVM'26 Leverage the video generative models to generate extenable 3D scenes. arXiv |
|
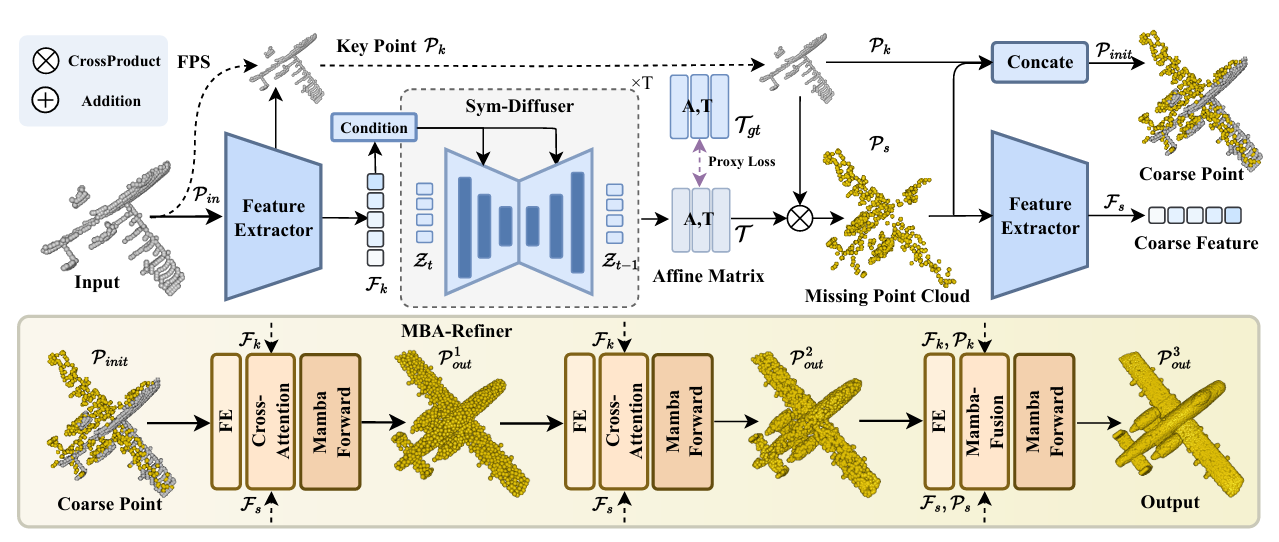
Simba: Towards High-Fidelity and Geometrically-Consistent Point Cloud Completion via Transformation Diffusion
Lirui Zhang*, Zhengkai Zhao*, Zhi Zuo, Pan Gao, Jie Qin, In AAAI'26 Point Cloud Completion via transformation diffusion. |
|
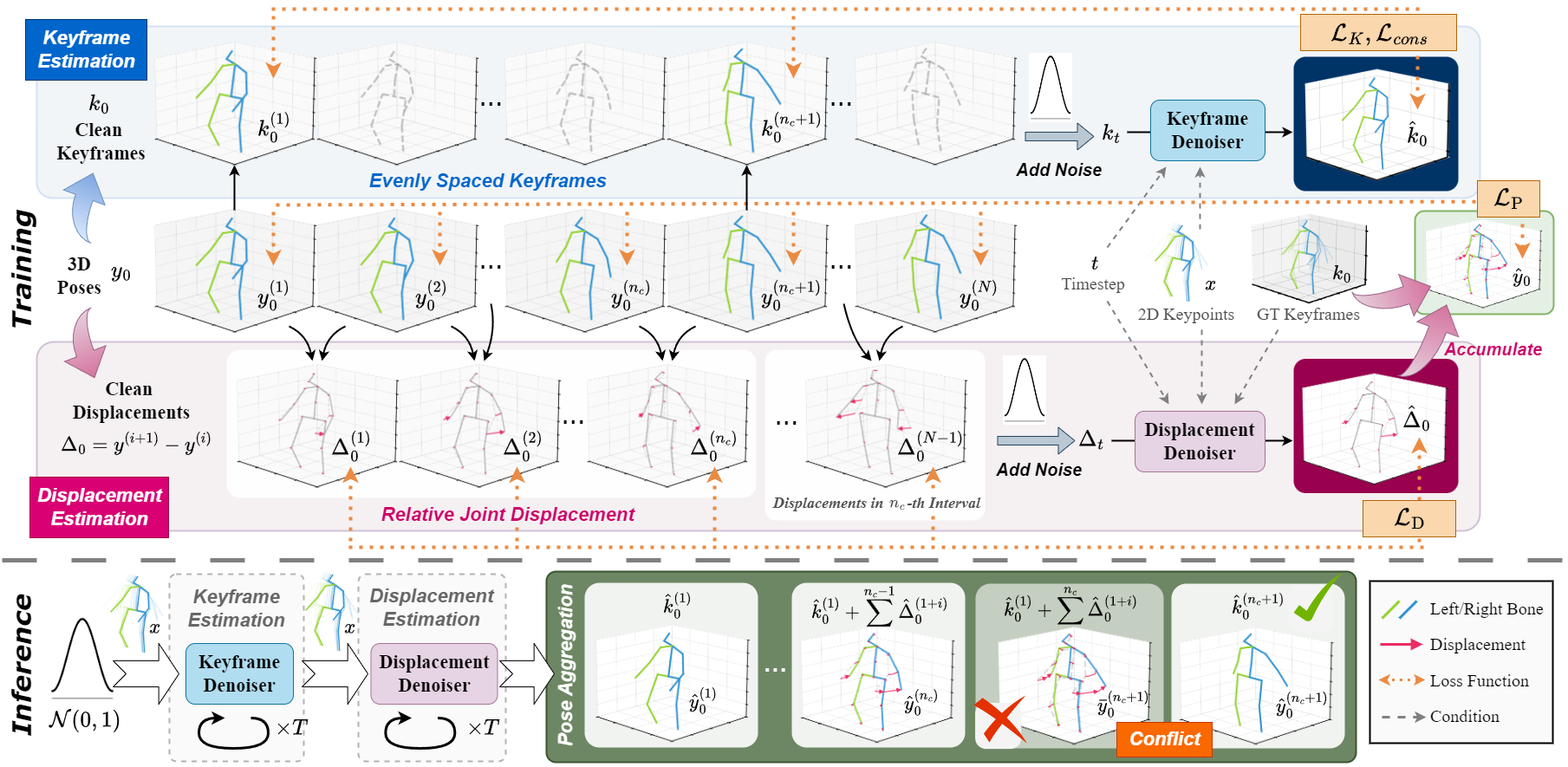
MvP: Learning Motion Prior for Diffusion-Based 3D Human Pose Estimation.
Bing Han, Chenyi Zhuang, Zhi Zuo, Pan Gao, Nicu Sebe, Under Review Leverage the diffusion models to estimate 3D human pose from 2D images. |
What's More?"A believing heart is a magic" and "Just Do It" |